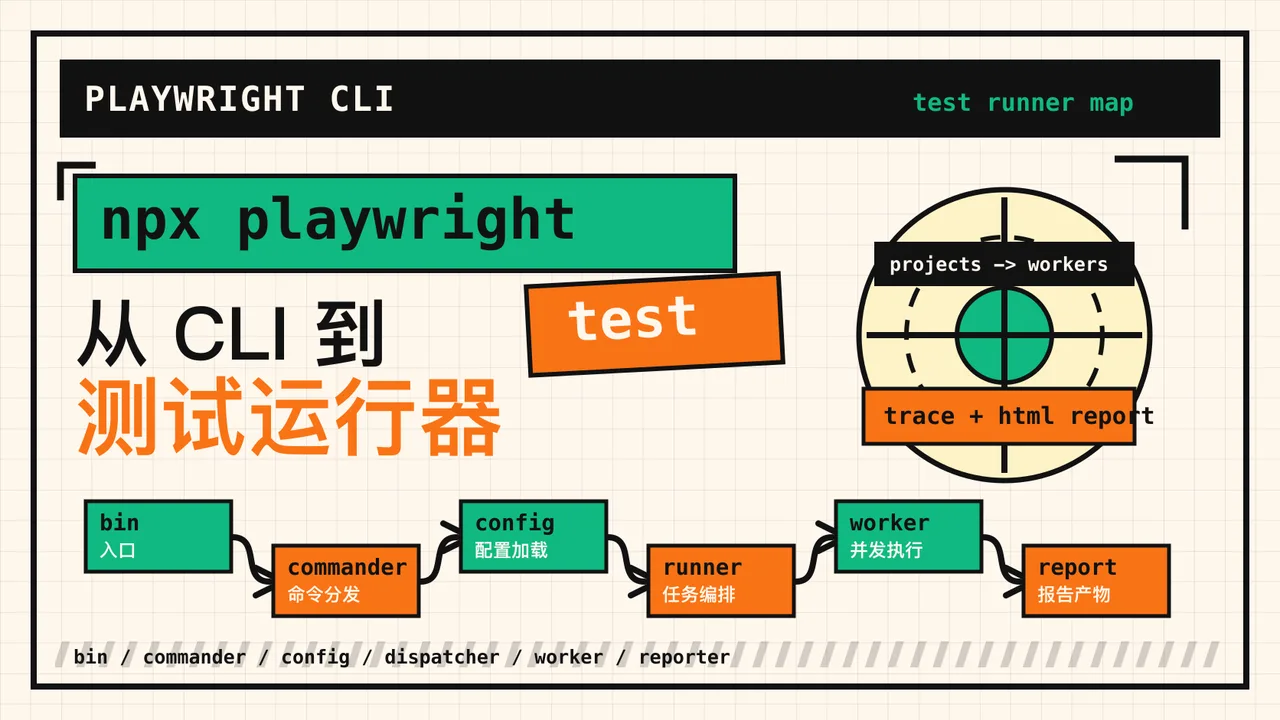
摘要
这篇文章只聚焦一个问题:
当我们执行 npx playwright ... 时,Playwright CLI 背后到底发生了什么?
我这次观察到的源码状态是:
| 项目 | 观察值 |
|---|---|
| 官方仓库 | microsoft/playwright |
| 许可证 | Apache-2.0 |
| npm latest | playwright@1.59.1、@playwright/test@1.59.1 |
| 本文观察源码 commit | 8d548bcd48d13d9966d9f52863905cbe486cc259 |
| 源码 package version | 1.60.0-next |
| 观察日期 | 2026-04-26 |
一句话概括 Playwright CLI:
它不是一个薄薄的命令行包装,而是 Playwright 工具链的总入口:底层命令来自 playwright-core,测试和报告命令来自 playwright / @playwright/test,最后通过 commander 分发到浏览器启动、浏览器安装、代码录制、trace、HTML report 和测试运行器。

下面所有代码片段都是基于源码的裁剪讲解版:
- 不原样搬运完整源码
- 只保留表达设计意图的关键路径
- 每一行都写中文注释
- 真实源码以文中的 commit 链接为准
0. 先分清三个包
理解 Playwright CLI,先不要从 test 命令开始,而要先分清三个 npm 包。
| 包 | bin | 主要职责 |
|---|---|---|
playwright-core |
playwright-core |
核心浏览器自动化、浏览器安装、open / codegen / screenshot / pdf / trace 等基础命令 |
playwright |
playwright |
依赖 playwright-core,并在核心命令之上加入 Playwright Test 相关命令 |
@playwright/test |
playwright |
依赖 playwright,提供最常见的测试框架入口 |
所以通常执行的:
npx playwright test
并不是直接落到 @playwright/test 自己的一套 CLI 实现里。@playwright/test/cli.js 会加载 playwright/lib/program,而 playwright/lib/program 又会先装配 playwright-core 的基础命令,再装配测试命令。
入口文件的讲解版可以写成这样:
#!/usr/bin/env node // 让 npm / npx 把这个文件当成可执行脚本
const { program } = require("./lib/program"); // 载入已经装配好命令的 commander program
program.parse(process.argv); // 把当前进程参数交给 commander 解析并分发
这三行解释了 CLI 的第一层边界:bin 文件本身几乎不做业务逻辑,只负责把控制权交给 program。
1. 命令是被两层 decorator 装进去的
Playwright CLI 的命令注册不是集中在一个巨型文件里,而是拆成两层。
第一层在 playwright-core:
opencodegeninstalluninstallinstall-depscr/ff/wkscreenshotpdfshow-tracetrace ...- 一些隐藏的 driver / server / cli 命令
第二层在 playwright:
testshow-reportmerge-reportsclear-cache- 隐藏的
test-server - 隐藏的
run-test-mcp-server init-agents
核心装配逻辑可以简化成这样:
libCli.decorateProgram(program); // 先注册 playwright-core 提供的浏览器、安装、trace 等基础命令
addTestCommand(program); // 再注册 playwright test 命令,把它接到测试运行器
addShowReportCommand(program); // 注册 show-report,用来启动 HTML report 查看服务
addMergeReportsCommand(program); // 注册 merge-reports,用来合并分片测试产生的 blob report
addClearCacheCommand(program); // 注册 clear-cache,用来清理构建和测试缓存
这个设计有一个很现实的收益:playwright-core 可以作为不带测试框架的基础自动化包存在;playwright / @playwright/test 可以在同一个命令名下补上测试能力。

如果只安装了 playwright-core,它也会给 test、show-report、merge-reports 放一个 stub。这个 stub 不会真的运行测试,而是提示你安装 @playwright/test。这比直接报“未知命令”更友好,因为用户通常是从文档里的 npx playwright test 开始接触 Playwright。
2. test 命令的第一步:把 CLI 参数变成配置覆盖
playwright test 是 CLI 中最复杂的命令。它的入口在 packages/playwright/src/cli/testActions.ts。
用户写在命令行里的参数,例如:
npx playwright test tests/login.spec.ts --project=chromium --headed --retries=2 --trace=on
不会直接散落到执行器里。Playwright 会先把它们整理成两类数据:
| 数据 | 作用 |
|---|---|
cliOverrides |
覆盖配置文件里的 timeout、retries、workers、reporter、use.trace、use.headless 等选项 |
TestRunOptions |
描述本次要跑哪些测试:文件过滤、grep、project、shard、last-failed、test-list 等 |
讲解版代码如下:
const cliOverrides = overridesFromOptions(opts); // 把 --headed、--retries、--trace 等参数转换成配置覆盖
const config = await configLoader.loadConfigFromFile(opts.config, cliOverrides, opts.deps === false); // 加载 playwright.config 并合并 CLI 覆盖
const options = { locations: args.length ? args : undefined, projectFilter: opts.project }; // 把位置参数和 project 参数整理成测试运行选项
const status = await testRunner.runAllTestsWithConfig(config, options); // 把配置和运行选项交给测试运行器
gracefullyProcessExitDoNotHang(status === "passed" ? 0 : 1); // 根据测试结果决定进程退出码
这里最重要的是“覆盖”这个词。
Playwright 的配置来源不止一个:
- 默认配置
playwright.config.ts- project 级别配置
- 命令行参数
- 少量环境变量,例如
PWDEBUG、PWPAUSE
CLI 参数并不是另起一套逻辑,而是被转换成配置覆盖,再进入统一的配置模型。这样后面的测试加载、worker 调度、reporter、trace、video 都只需要面对一个完整的 FullConfigInternal。
3. 配置加载不只是 require(config)
Playwright 支持 TypeScript 配置、ESM 配置、defineConfig() 合并、project 继承、web server、transform、source map 等能力。所以配置加载比普通 CLI 复杂得多。
configLoader 主要做这些事:
- 注册或配置 ESM loader。
- 读取用户配置文件。
- 校验字段类型,例如
forbidOnly、grep、projects、reporter、shard。 - 创建内部完整配置对象。
- 读取 transform / tsconfig 设置。
- 把 transform 配置同步给 ESM loader。
讲解版代码如下:
await configureESMLoader(); // 先准备 ESM 和 TypeScript 加载能力
const userConfig = await loadUserConfig(location); // 读取用户的 playwright.config 文件
validateConfig(location.resolvedConfigFile || "<default>", userConfig); // 在进入运行器前校验配置形状
const fullConfig = new FullConfigInternal(location, userConfig, overrides || {}, metadata); // 把默认值、用户配置和 CLI 覆盖合成内部配置
await configureESMLoaderTransformConfig(); // 把 transform 配置传给后续测试文件加载流程
这也是为什么 Playwright CLI 能直接跑 .ts 测试文件。CLI 不是简单把测试文件交给 Node,它会在加载配置和测试文件前准备自己的 transform 层。
4. 测试运行器:用任务链描述一次测试
进入 runAllTestsWithConfig() 后,Playwright 会把一次测试运行拆成一串任务。
普通测试运行大概是这条链:
const tasks = [ // 用任务数组描述一次完整测试运行
createApplyRebaselinesTask(), // 开始前清理快照 rebaseline 建议,结束时再按策略应用
...createGlobalSetupTasks(config), // 执行插件 setup、globalSetup,并安排 globalTeardown
createLoadTask("in-process", { filterOnly: true, failOnLoadErrors: true }), // 收集、加载、过滤测试用例
...createRunTestsTasks(config), // 创建执行阶段、启动 worker、运行测试并汇报结果
]; // 任务链定义结束
这个任务链是 Playwright Test 的骨架。

其中最关键的是 createLoadTask() 和 createRunTestsTasks()。
createLoadTask() 做的是“把文件变成测试树”:
- 根据 project 收集测试文件
- 应用命令行路径过滤
- 应用
grep/grepInvert - 处理
test-list/test-list-invert - 处理
only-changed - 加载测试文件,生成 file suite
- 处理
test.only - 处理 shard
- 处理 project 依赖
- 生成最终 root suite
createRunTestsTasks() 做的是“把测试树变成并发执行”:
- 按 project 依赖创建 phase
- 每个 phase 内生成 test group
- 用 dispatcher 分发 test group
- 启动或复用 worker 进程
- 收集 stdout / stderr / error / result
- 调 reporter 输出结果
也就是说,playwright test 不是“一边扫描一边跑”。它会先形成一棵稳定的测试树,再根据 project、shard、依赖和 worker 数量切成可调度的执行单元。
5. phase 和 worker:并发不是简单 Promise.all
Playwright 支持 project 依赖,例如先跑 setup project,再跑 chromium / firefox / webkit project。它还支持 project 级 worker 限制、失败重试、worker 复用和 worker 崩溃隔离。
因此它不能把所有测试文件直接丢进 Promise.all()。
它会先把 project 拆成 phase:一个 phase 里的 project 可以并行;下一个 phase 必须等依赖完成。
然后 dispatcher 在 phase 内调度 test group。简化后是这个逻辑:
const job = pickRunnableTestGroup(queue); // 从队列里挑出一个满足 project worker 限制的测试组
const worker = reuseWorkerWithSameHash(job) || createWorker(job); // 优先复用环境相同的 worker,否则启动新 worker
worker.runTestGroup(job.payload); // 把测试组发送给 worker 子进程执行
const result = await job.result; // 等待 worker 回传测试结果
if (result.didFail) await worker.stop(true); // 失败后停止该 worker,避免污染后续测试
if (result.newJob) queue.unshift(result.newJob); // 如果有剩余测试或 retry,就把新任务放回队列头部
这里的 workerHash 很关键。它代表一组测试能否复用同一个 worker 环境。环境一致时复用 worker 可以减少启动成本;环境不一致或 worker 出错时就要重启,避免状态泄漏。
WorkerHost 本质上是一个子进程包装器。它启动的是 workerProcessEntry.js,并通过 IPC 把序列化配置、project id、parallel index、artifacts 目录等传进去。
讲解版代码如下:
const worker = new WorkerHost(testGroup, { parallelIndex, config, outputDir }); // 为某个测试组创建 worker 子进程宿主
await worker.start(); // 启动 workerProcessEntry,并建立 IPC 通道
worker.runTestGroup(runPayload); // 把测试组和运行参数发送给 worker
worker.on("stdOut", chunk => reporter.onStdOut?.(chunk)); // 把 worker 标准输出转交给 reporter
worker.on("stdErr", chunk => reporter.onStdErr?.(chunk)); // 把 worker 标准错误转交给 reporter
这个模型解释了很多日常现象:
- 为什么
--workers=1更容易复现顺序问题 - 为什么某个 worker 失败后后续测试可能换新进程
- 为什么 project 依赖会影响整体并发
- 为什么 trace、screenshot、video 都能按 test result 归档
6. open、codegen、screenshot、pdf 共用一套浏览器启动层
Playwright CLI 不只有测试命令。open、codegen、screenshot、pdf 都是面向浏览器的实用命令。
这些命令的共同入口是 launchContext()。
它负责把 CLI 参数转换成浏览器启动选项和 context 选项:
--browser/-b--channel--device--viewport-size--geolocation--user-agent--lang--timezone--proxy-server--load-storage--save-storage--save-har--user-data-dir

讲解版代码如下:
const browserType = lookupBrowserType(options); // 根据 --browser 或设备默认值选择 chromium、firefox、webkit
const contextOptions = options.device ? { ...playwright.devices[options.device] } : {}; // 把设备描述符复制成 context 初始配置
if (options.viewportSize) contextOptions.viewport = parseViewport(options.viewportSize); // 把 --viewport-size 转成宽高对象
if (options.loadStorage) contextOptions.storageState = options.loadStorage; // 复用已有登录态和本地存储
const browser = await browserType.launch(launchOptions); // 启动浏览器进程
const context = await browser.newContext(contextOptions); // 在浏览器里创建隔离上下文
open 做的事情最少:启动 context,打开页面,然后让用户自己操作。
screenshot 和 pdf 会额外等待选择器或等待时间,然后输出文件。
codegen 则多一步 recorder:
const tracesDir = path.join(os.tmpdir(), `playwright-recorder-trace-${Date.now()}`); // 为录制过程准备临时 trace 目录
const { context } = await launchContext(options, { headless: false, tracesDir }); // 用可视浏览器启动一个上下文
await context._enableRecorder({ language, mode: "recording", outputFile }); // 启用 recorder,把用户操作翻译成目标语言代码
await openPage(context, url); // 打开起始页面,后续点击和输入由 recorder 监听
这说明 codegen 不是独立工具。它复用了 Playwright 的真实浏览器上下文,然后在 context 上打开 recorder 能力。
7. install 命令:浏览器二进制是版本化资产
npx playwright install 看起来只是下载浏览器,但源码里它背后是一套 registry。
Playwright 要解决的问题是:
- 同一个 Playwright 版本需要匹配特定浏览器 revision
- 不同平台的下载地址和可执行文件路径不同
- Chromium、Firefox、WebKit、ffmpeg、headless shell 的安装策略不同
- Linux 还需要系统依赖校验
- 同一台机器可能有多个 Playwright 版本共用浏览器缓存
install 的讲解版代码如下:
const executables = registry.resolveBrowsers(args, { shell }); // 把 chromium、firefox、webkit 等参数解析成待安装资产
if (options.withDeps) await registry.installDeps(executables, !!options.dryRun); // 如果传了 --with-deps,先安装系统依赖
await registry.install(executables, { force: options.force }); // 下载并安装对应版本的浏览器二进制
await registry.validateHostRequirementsForExecutablesIfNeeded(executables, "javascript"); // 安装后校验当前系统是否满足运行要求
所以 Playwright 推荐执行 npx playwright install,不是因为它不能找到系统浏览器,而是因为测试稳定性需要“框架版本”和“浏览器 revision”可控。
这和普通用户打开 Chrome 不一样。端到端测试最怕的是环境漂移:今天 CI 升了浏览器,明天截图基线变了,后天 WebKit 行为和本地不一致。Playwright 用 registry 把这种漂移尽量收束到版本管理里。
8. report 和 trace:CLI 也是证据入口
端到端测试失败后,单纯退出码不够。Playwright CLI 还负责把失败证据打开、合并和检查。
show-report 的职责很窄:找到 HTML report 目录,启动本地服务,打开浏览器查看。
merge-reports 面向分片测试。多个 shard 可以分别生成 blob report,最后由 CLI 合并成一个报告。
show-trace 面向可视化 trace viewer。除此之外,源码里还新增了一组 trace 子命令,可以从命令行检查 trace:
trace opentrace actionstrace actiontrace requeststrace requesttrace consoletrace errorstrace snapshottrace screenshottrace attachments

这说明 Playwright 对 trace 的定位已经不只是“打开一个 GUI 看看”。它也在把 trace 变成可被脚本、终端和 AI 工具消费的结构化证据。
讲解版命令注册如下:
const traceCommand = program.command("trace"); // 在主 CLI 下创建 trace 命令组
traceCommand.command("actions").action(options => traceActions(options)); // 列出 trace 里的用户动作
traceCommand.command("requests").action(options => traceRequests(options)); // 列出 trace 里的网络请求
traceCommand.command("console").action(options => traceConsole(options)); // 列出浏览器 console 和 stdio 信息
traceCommand.command("snapshot <action-id>").action((id, options) => traceSnapshot(id, options)); // 对某个动作的 DOM snapshot 做进一步检查
从工程角度看,这条线很重要。测试工具的价值不只是“跑”,还包括失败后能不能低成本定位问题。
9. 为什么 CLI 里会出现 MCP 和 agents
在本文观察的源码里,packages/playwright/src/program.ts 还注册了两个和传统测试不完全一样的入口:
run-test-mcp-serverinit-agents
它们说明 Playwright CLI 正在承担新的角色:把测试运行器、浏览器能力、trace 证据和 AI coding agent 串起来。
这并不奇怪。Playwright 本来就有几个适合 agent 的能力:
- 可以结构化访问页面
- 可以稳定执行用户动作
- 可以记录 trace
- 可以生成测试代码
- 可以用 reporter 输出机器可读结果
CLI 则是最自然的集成层。它既能被人手动调用,也能被编辑器、CI、MCP server、agent workflow 调用。
但这里也要保持边界感。Playwright CLI 的核心仍然是浏览器自动化和测试工具链。MCP / agents 是在这个工具链上扩展出来的入口,不应该反过来遮住 test、codegen、trace 这些基础能力。
10. 这套实现的设计取舍
看完源码后,我觉得 Playwright CLI 有几个值得学习的取舍。
第一,bin 入口极薄,业务逻辑放到可测试模块里。
cli.js 只做 program.parse(process.argv)。这让入口稳定,也让真实逻辑可以被不同包复用。
第二,核心命令和测试命令分层。
playwright-core 保持基础自动化能力,playwright / @playwright/test 补上测试运行器。这样包边界和用户入口可以同时成立。
第三,CLI 参数先归一成配置覆盖。
后续模块不需要到处理解 --headed、--trace、--workers 的原始形态,只需要面对内部配置对象。
第四,测试执行用任务链表达生命周期。
global setup、加载、过滤、分片、phase、worker、reporter 都在任务模型里串起来,比把所有逻辑堆在一个 run() 里更容易维护。
第五,worker 调度有明确的隔离边界。
它既复用相同环境的 worker,又在失败后主动停止 worker。这是在速度和可靠性之间做的务实平衡。
第六,CLI 不只负责运行,也负责证据消费。
HTML report、trace viewer、trace 子命令、merge report 都让一次测试失败后留下可分析的证据。
参考源码
本文主要阅读了这些源码文件:
| 文件 | 作用 |
|---|---|
packages/playwright/cli.js |
playwright 包的 bin 入口 |
packages/playwright-test/cli.js |
@playwright/test 包的 bin 入口 |
packages/playwright-core/cli.js |
playwright-core 包的 bin 入口 |
packages/playwright/src/program.ts |
测试和报告命令注册 |
packages/playwright-core/src/cli/program.ts |
基础浏览器命令注册 |
packages/playwright/src/cli/testActions.ts |
playwright test 的动作入口 |
packages/playwright/src/common/configLoader.ts |
配置加载、校验和 transform 设置 |
packages/playwright/src/runner/testRunner.ts |
测试运行器主流程 |
packages/playwright/src/runner/tasks.ts |
测试生命周期任务链 |
packages/playwright/src/runner/dispatcher.ts |
test group 到 worker 的调度 |
packages/playwright/src/runner/workerHost.ts |
worker 子进程宿主 |
packages/playwright-core/src/cli/browserActions.ts |
open / codegen / screenshot / pdf 的浏览器上下文入口 |
packages/playwright-core/src/cli/installActions.ts |
浏览器安装命令入口 |
packages/playwright-core/src/tools/trace/traceCli.ts |
trace 子命令注册 |
总结
Playwright CLI 的实现可以分成三句话:
cli.js是极薄入口,真正命令由program装配。playwright-core提供浏览器、安装、录制、trace 等基础命令,playwright/@playwright/test在同一个 CLI 上补测试和报告能力。playwright test会把 CLI 参数归一成配置覆盖,再进入“配置加载 -> 测试发现 -> suite 构建 -> phase 生成 -> dispatcher 调度 -> worker 执行 -> reporter / trace / report 输出”的完整流水线。
所以 Playwright CLI 值得看的地方,不是“它用了 commander”这么简单,而是它怎样把一个浏览器自动化库组织成可安装、可调试、可录制、可报告、可并发、可进入 CI 和 agent workflow 的工程化入口。