摘要
这篇文章解读的是 Generative Agents: Interactive Simulacra of Human Behavior。它是 2023 年那篇很出圈的 “AI 小镇” 论文:作者在一个类似 The Sims 的沙盒环境 Smallville 里放了 25 个由大语言模型驱动的角色,让他们起床、吃饭、上班、聊天、记住彼此、传播消息,并在用户只给一个角色种下“想办情人节派对”的想法后,自动扩散邀请、形成约会、装修咖啡馆,最后真的有人按时出现。
这不是逐段直译,而是一篇中文解读和关键内容意译。原论文很长,包含大量 prompt、实验流程和交互细节;这里会保留主线、方法、实验数字和我的理解,避免把整篇论文机械翻译成一份难读的中文稿。
先把论文信息对齐:
| 项目 | 内容 |
|---|---|
| 论文 | Generative Agents: Interactive Simulacra of Human Behavior |
| 作者 | Joon Sung Park、Joseph C. O'Brien、Carrie J. Cai、Meredith Ringel Morris、Percy Liang、Michael S. Bernstein |
| arXiv | 2304.03442,v1 提交于 2023-04-07,v2 修订于 2023-08-06 |
| 会议 | UIST 2023 |
| DOI | 10.48550/arXiv.2304.03442,ACM 版本 DOI 为 10.1145/3586183.3606763 |
| 论文代码 | joonspk-research/generative_agents |
| 我的阅读时间 | 2026-04-28 |
用一句话概括这篇论文:
Generative Agents 的核心不是“让 LLM 扮演角色”,而是给 LLM 外面加一套长期记忆、动态检索、反思总结和递归计划机制,让角色的下一步行为能被过去经历、当前环境和未来安排共同约束。

0. 先把题目翻成人话
论文标题可以译成:
生成式智能体:人类行为的交互式拟像。
这里的 simulacra 不应该理解成“真正的人”。它更接近“可交互的行为拟像”:角色不拥有真实人的意识、动机和责任能力,但它们的外显行为可以在一定场景里让观察者觉得连贯、可信、像一个有生活轨迹的人。
这也是论文反复强调的边界。作者说角色会起床、做早餐、上班、聊天、记住过去、规划明天,这些都是为了描述它们在交互系统里的可观察行为,并不是说这些软件实体拥有真实主体性。
1. 论文摘要的中文意译
下面是我根据原摘要做的压缩版中文意译,不是逐句翻译:
可信的人类行为代理可以支持很多交互应用,比如沉浸式环境、人际沟通排练空间和原型设计工具。本文提出生成式智能体,也就是能够模拟可信人类行为的软件智能体。它们会醒来、做饭、去工作;艺术家会画画,作家会写作;它们会形成观点、注意到彼此、主动交谈;它们会记住过去几天的经历,并在规划明天时利用这些记忆。
为了实现这种智能体,论文提出一套架构:用自然语言保存智能体完整的经验记录,随着时间把这些记忆综合成更高层的反思,再在需要行动时动态检索相关记忆,辅助计划和行为生成。作者把这套智能体放进一个受 The Sims 启发的交互式沙盒小镇,用户可以用自然语言和 25 个角色互动。
评估显示,这些角色能产生可信的个体行为和涌现式社交行为。例如,只要用户给一个角色设定“想办情人节派对”,接下来两天里,角色会自主传播邀请、结识新朋友、互相约去派对,并协调在正确时间一起出现。消融实验说明,观察、计划和反思这三个组件都显著影响行为可信度。论文由此提出了把大语言模型和交互式计算智能体结合起来的一组架构模式。
如果再压缩一点:
这篇论文要证明的是:LLM 本身可以生成一段像人的回复,但要让一个角色在开放世界里连续生活两天,就必须管理它的记忆、抽象经验,并把长期计划和即时反应接起来。
2. 它到底解决了什么问题
很多人第一次看到这篇论文,会以为重点是“25 个 ChatGPT NPC 很会聊天”。其实这只是表层效果。
论文真正处理的是一个更基础的问题:
如何让一个由 LLM 驱动的角色,在不断变化的环境里保持长期连贯?
只把角色设定塞进 prompt 里,会遇到几个问题:
- 角色今天发生了很多事,明天 prompt 放不下所有经历。
- 角色需要知道哪些记忆和当前场景有关,而不是把全部历史混进上下文。
- 角色不能只看当下,否则会出现刚吃完饭又吃饭、刚见过人却不记得的行为。
- 角色需要从一堆低层事件里总结高层判断,比如“我和某人关系更近了”“我最近很在意研究项目”。
- 多个角色同时生活时,消息扩散、关系形成和协作行为会互相影响。
所以这篇论文的关键贡献不是某个单一 prompt,而是一套围绕 LLM 的外部认知架构。
3. Smallville:论文里的 AI 小镇
作者搭了一个叫 Smallville 的沙盒世界。它是一个像 The Sims 的 2D 小镇,里面有咖啡馆、酒吧、公园、学校、宿舍、住宅、商店等地点。每个地点还会继续拆成区域和物体,例如房子里有厨房,厨房里有炉子。
小镇里有 25 个角色。每个角色一开始只有一段自然语言简介,里面写着姓名、职业、性格、家庭关系、认识谁、不认识谁、当前目标等信息。系统会把这段简介按分号切成初始记忆,放进角色的记忆流里。
角色每个时间步都会输出一个自然语言动作,比如“Isabella 正在写日记”“John 正在柜台给顾客准备药”。沙盒服务端再把这个动作翻译成游戏里的移动、位置、对象状态变化和界面展示。
这一步很重要,因为它把两个世界接了起来:
- LLM 的世界是自然语言。
- 游戏引擎的世界是 JSON、坐标、对象、状态和路径。
Smallville 的实现就是在这两者之间来回翻译。

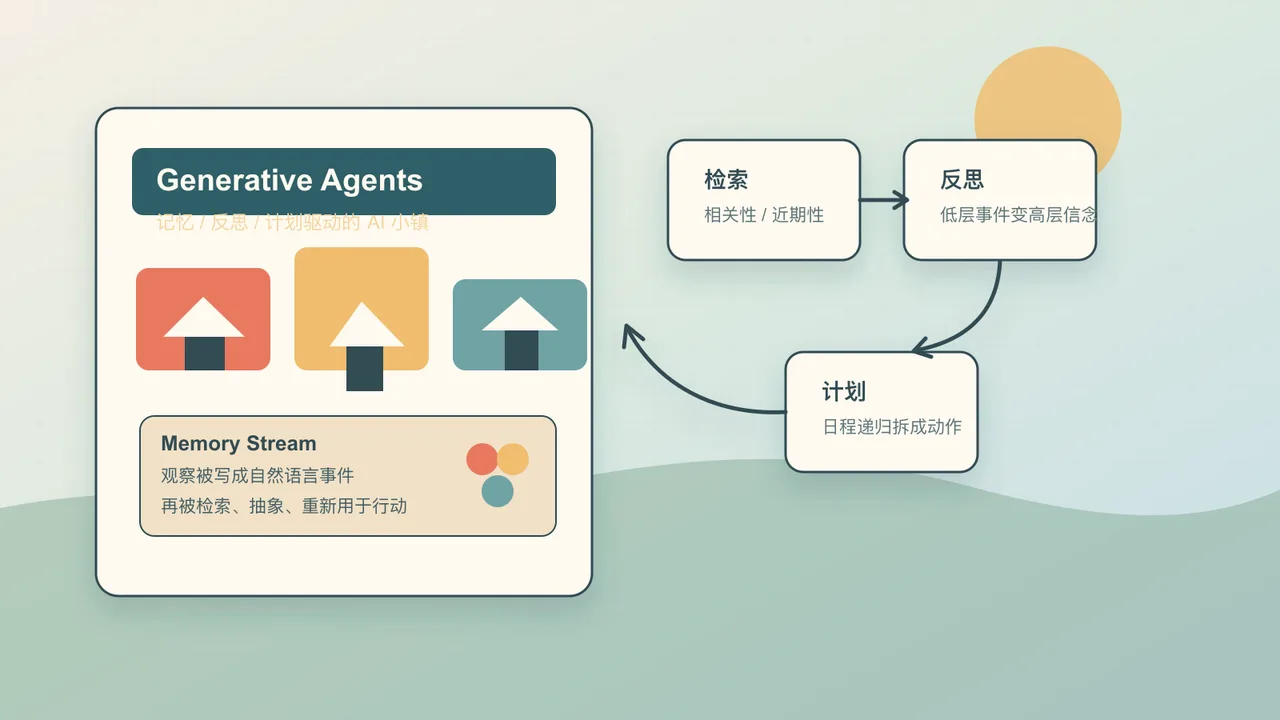
4. 架构核心:记忆流、检索、反思、计划
这篇论文最值得反复看的部分是第 4 节的架构。它可以拆成四个层次。
4.1 记忆流:把经历当成可检索事件日志
每个角色都有一个 memory stream,也就是记忆流。它不是人脑记忆的真实模型,而是一个工程上的事件日志。
每条记忆大致包含:
- 一段自然语言描述
- 创建时间
- 最近访问时间
- 重要性分数
- 后续可能还会被反思引用
最基础的记忆叫 observation,也就是观察。比如:
- Isabella 正在摆出糕点
- Maria 一边喝咖啡一边准备化学考试
- Isabella 和 Maria 在聊情人节派对
- 冰箱空了
关键点是:所有经历都先被写成自然语言,再进入同一个记忆系统。 这让 LLM 可以直接消费记忆,而不需要一套复杂的符号推理语言。
4.2 检索:不是全塞上下文,而是按当前问题找记忆
记忆越来越多以后,不能每次都把所有记录塞进 prompt。论文用了一个检索函数,综合三个维度给记忆打分:
| 维度 | 含义 | 论文里的做法 |
|---|---|---|
recency 近期性 |
最近访问过的记忆更容易进入注意范围 | 按沙盒游戏时间做指数衰减,衰减因子是 0.995 |
importance 重要性 |
重大事件比琐事更该被想起 | 让 LLM 给记忆打 1 到 10 分 |
relevance 相关性 |
和当前场景语义相近的记忆更重要 | 用 embedding 计算当前查询和记忆的余弦相似度 |
最后把三项归一化到 [0, 1],再做加权求和。论文实现里三个权重都设为 1。
用裁剪版伪代码写出来,大概是这样:
type Memory = { text: string; lastAccessedAt: number; importance: number }; // 定义一条记忆,保留文本、最近访问时间和重要性
type Query = { text: string; now: number }; // 定义当前查询,保留查询文本和当前沙盒时间
function score(memory: Memory, query: Query) { // 计算一条记忆对当前查询的可用程度
const recency = decay(query.now - memory.lastAccessedAt); // 用时间差计算近期性,越近分数越高
const importance = normalize(memory.importance); // 把 LLM 评出的重要性分数归一化
const relevance = cosine(embed(memory.text), embed(query.text)); // 用向量相似度估计语义相关性
return recency + importance + relevance; // 论文实现里三项权重相同,直接相加
} // 记忆打分结束
function retrieve(memories: Memory[], query: Query) { // 从记忆流里取出要放进 prompt 的记忆
return memories.sort((a, b) => score(b, query) - score(a, query)); // 按当前查询分数从高到低排序
} // 检索流程结束
这个设计现在看起来并不陌生,但在 2023 年上半年,它很清楚地把“LLM Agent 需要外部记忆系统”这件事讲成了一个可复用模式。
4.3 反思:把低层事件压缩成高层判断
只有观察记忆还不够。角色可能记得“我和某人聊过几次”,但不会自然形成“我们有共同兴趣”这种抽象判断。
所以论文引入第二类记忆:reflection,也就是反思。
它的生成流程大概是:
- 取最近一批记忆。
- 让 LLM 提出几个“可以从这些记录里回答的高层问题”。
- 用这些高层问题再去检索相关记忆。
- 让 LLM 总结洞察,并要求它标注依据来自哪些记忆。
- 把这些洞察写回记忆流,成为以后可检索的新记忆。
论文实现里,当最近事件的重要性累计超过阈值 150 时触发反思。实际模拟中,角色大约每天反思 2 到 3 次。
这一步的意义很大。因为它相当于给 Agent 做了一层“抽象缓存”:
- 原始观察是低层事实。
- 反思是从事实里总结出来的高层信念。
- 未来行为不只检索事实,也检索这些信念。
比如 Klaus 曾经多次读城市更新相关书籍、写研究论文、和别人讨论研究项目。反思模块会把这些事件综合成“Klaus 很投入自己的研究”。之后当他被问到想和谁共度一小时,系统就不只是数谁出现次数最多,而是能把“共同研究兴趣”纳入判断。
4.4 计划:先定一天,再递归拆成小动作
LLM 很擅长对当前情境给出一个看起来合理的动作,但如果每 30 分钟都重新问一次“现在该干什么”,角色可能会不断重复短期最合理行为。
论文里的例子是:如果只问模型当前 12 点、12 点半、1 点该做什么,Klaus 可能会连着吃几顿午饭。因为每个单点看,吃午饭都合理;但放到一天里就不合理。
所以论文让角色先生成粗粒度日程,再递归拆细:
- 先根据角色简介、最近经历和昨天总结,生成今天的大纲。
- 把大纲拆成几个小时级别的安排。
- 再把小时级安排拆成 5 到 15 分钟的动作。
- 当前环境变化时,允许角色反应并从当前时间重新规划。
这也是今天很多 Agent 框架仍然绕不开的问题:没有计划,Agent 就只有即时反应;没有重规划,计划又会变成死脚本。
5. 反应和对话:让角色被环境打断
Smallville 里的角色不是只按日程走。每个时间步,它们会感知附近角色和物体状态,把观察写进记忆流,再判断要不要反应。
比如 Isabella 正在做早餐时,用户把厨房炉子的状态改成“正在燃烧”。她下一步会注意到这个状态,停止原计划,去关掉炉子并重新准备早餐。
角色之间对话也是类似机制:
- John 看到 Eddy 在花园里走动。
- John 检索自己关于 Eddy 的记忆,知道 Eddy 是儿子、正在做音乐作业、喜欢边走边思考。
- 系统判断 John 可以关心一下 Eddy 的作业。
- LLM 生成 John 的第一句话。
- Eddy 再从自己的角度检索关于 John、关于音乐作业、关于刚才对话的记忆。
- Eddy 决定是否回应,以及怎么回应。
这个流程让对话不是孤立的聊天,而是由关系、地点、当前行为和历史记忆共同条件化。

6. 实验怎么做
论文做了两类评估:一个是受控评估,一个是端到端小镇模拟。
6.1 受控评估:采访角色,看回答是否可信
作者利用了一个很自然的评测方式:既然角色能用自然语言对话,那就直接“采访”它们。
采访问题覆盖五类能力:
| 类别 | 评测目标 |
|---|---|
| 自我认知 | 能不能保持自己的身份、职业、性格和日程 |
| 记忆 | 能不能回答过去见过谁、听过什么消息 |
| 计划 | 能不能说出明天某个时间会做什么 |
| 反应 | 面对突发情境时能不能做出合理反应 |
| 反思 | 能不能基于经历做高层判断,例如更想和谁相处 |
实验里,100 名评估者会看某个角色的回放和记忆流,然后比较五种条件下生成的回答可信度:
- 完整架构
- 去掉反思
- 去掉反思和计划
- 去掉观察、反思和计划
- 人类众包作者写的角色回答
这里的人类条件不是专家上限,而是一个基础人类基线。论文也明确说,众包回答并不代表“最佳人类角色扮演”。
6.2 受控评估结果:完整架构最高
论文用 TrueSkill 分数表示排序结果。主要数字是:
| 条件 | TrueSkill 均值 |
|---|---|
| 完整架构 | 29.89 |
| 去掉反思 | 26.88 |
| 去掉反思和计划 | 25.64 |
| 人类众包基线 | 22.95 |
| 去掉观察、反思和计划 | 21.21 |
Kruskal-Wallis 检验显示总体差异显著,Dunn 事后检验显示除“众包基线”和“完全去记忆基线”之外,其余两两差异都显著。
这个结果支持了论文的主张:记忆、计划和反思不是装饰模块。去掉任何一层,行为可信度都会下降。
不过这里也要谨慎读:
- 评测的是“可信行为排序”,不是角色真的像人。
- 人类基线是普通众包写作,不是专业编剧或熟悉角色的人。
- 消融条件共用完整架构模拟后的记忆状态,这让比较更可控,但也不等同于每个架构自己独立跑两天后的真实表现。
6.3 端到端评估:两天小镇生活
端到端实验让 25 个角色连续在 Smallville 里互动两天,观察三类涌现行为:
- 信息扩散
- 关系形成
- 群体协调
论文报告的主要结果是:
| 现象 | 结果 |
|---|---|
| Sam 参选镇长的消息 | 知情角色从 1 个增加到 8 个,也就是 4% -> 32% |
| Isabella 情人节派对消息 | 知情角色从 1 个增加到 13 个,也就是 4% -> 52% |
| 关系网络密度 | 从 0.167 增加到 0.74 |
| 派对协调 | 12 个被邀请角色里,5 个最终出现在 Hobbs Cafe |
| 关系问答幻觉 | 453 个关于是否认识其他角色的回答里,幻觉比例是 1.3%,也就是 6 个 |
这些数字最有意思的地方是:系统没有给每个角色写死派对脚本。用户只给 Isabella 一个想办派对的初始意图,之后消息传播、装饰咖啡馆、邀请朋友、Maria 约 Klaus 一起去、几个人按时出现,都是架构运行后的结果。
这就是论文标题里的 interactive simulacra:它不只是一次生成一段文本,而是在可交互环境里持续生成行为轨迹。

7. 失败模式同样重要
这篇论文没有把系统写成完美产品。它列了不少失败模式,反而让文章更值得读。
7.1 检索失败
角色有时确实经历过某件事,但回答时没检索到相关记忆。
例如某个角色听过镇长竞选消息,但被问起时说自己没怎么关注。这不是模型完全不会记忆,而是外部记忆系统没有在当前查询下把正确片段捞出来。
这提醒我们:Agent 的记忆能力经常不是“有没有存”,而是“该想起来时能不能想起来”。
7.2 记忆修饰和幻觉
论文观察到,角色很少完全捏造自己没经历过的事情,但会对已有记忆做修饰。
比如角色知道 Sam 要参选,却额外补出“他明天会宣布”这种没有发生过的细节。另一个例子是把名叫 Adam Smith 的邻居误联想到现实历史上的经济学家 Adam Smith。
这类错误对 Agent 很危险,因为它不是彻底离谱的幻想,而是在真实记忆旁边加一点虚构细节。用户更难立刻发现。
7.3 空间常识不足
角色会把自然语言地点理解错。
比如宿舍里有一个 bathroom,但这个空间实际只能一个人使用。角色可能根据“宿舍卫生间”这个词联想到多人共用,于是走进已经有人占用的卫生间。商店晚上 5 点关门,但角色有时仍会在 5 点后进去,因为“关门”这个物理规范没有被清楚编码进状态。
这说明交互式 Agent 不只需要语言能力,还需要足够明确的世界状态和约束表达。
7.4 指令微调带来的过度礼貌
作者还注意到,底层模型的 instruction tuning 会影响角色风格。
角色对话有时过于正式、礼貌、合作。Isabella 在筹备派对时收到很多不符合她设定的建议,比如莎士比亚朗读、职业 networking 活动,但她很少拒绝。久而久之,别人的兴趣反而影响了她自己的兴趣。
这个问题今天仍然常见:很多 Agent 不是不会做事,而是过度顺从,缺少角色、目标和边界感。
8. 工程成本和现实限制
论文里有一个容易被忽略但很关键的细节:模拟 25 个角色两天,花了数千美元 token credits,并且跑了多天。
当时实现使用的是 gpt3.5-turbo 版本的 ChatGPT。作者也说,GPT-4 API 在写作时还处于邀请制,所以实验没有用 GPT-4。
这说明 Generative Agents 在概念上很漂亮,但工程上并不便宜:
- 每个角色每个时间步都可能需要感知、检索、判断、生成动作。
- 对话会触发双方多轮记忆检索。
- 反思会额外消耗模型调用。
- 环境越大,位置选择和对象状态判断越复杂。
- 角色越多,交互数量会迅速膨胀。
所以如果把这套思路迁移到真实产品,第一件事不是“多加几个 Agent”,而是认真设计调用预算、缓存、批处理、并行化、触发条件和失败回退。
9. 这篇论文对今天 Agent 系统的启发
我觉得它到今天仍然值得读,原因不是 Smallville 本身有多先进,而是它把 Agent 系统里几个基本问题讲得非常清楚。
9.1 记忆不是聊天记录,而是可检索的经验结构
很多系统把“长期记忆”理解成把聊天记录丢进向量库。Generative Agents 的设计更进一步:每条记忆有时间、有重要性、有访问记录,还会被反思模块引用和压缩。
这意味着记忆系统至少要回答三个问题:
- 什么值得存?
- 什么该被想起来?
- 低层事件何时应该变成高层判断?
9.2 反思是 Agent 的状态压缩机制
如果没有反思,Agent 每次都要从一堆碎片事件里重新推理。这样不仅贵,而且容易不稳定。
反思的价值是把经历压缩成可复用的语义状态。它像一个不断更新的摘要层,但又不是普通摘要,因为它仍然会作为记忆参与后续检索。
今天做个人助手、代码 Agent、客服 Agent 或游戏 NPC,只要任务跨越多个会话,都会遇到这个问题。
9.3 计划必须能被环境打断
纯计划会变死脚本,纯反应会变短视。论文的做法是先给角色一个日程骨架,再允许突发观察触发反应和重规划。
这对现实 Agent 很有启发:
- 代码 Agent 需要计划,但测试失败后要重规划。
- 运营 Agent 需要计划,但外部数据变化后要调整。
- 个人助手需要计划,但用户新指令优先级更高。
计划的价值不在于一开始就写对所有步骤,而在于让行为有一个可以被修改的上下文。
9.4 世界状态要有明确边界
Smallville 的失败案例说明,单靠自然语言描述空间不够。角色需要知道:
- 哪些地方开放,哪些地方关闭
- 哪些对象可用,哪些对象被占用
- 哪些动作违反物理约束
- 哪些关系是已知事实,哪些只是推测
今天做浏览器 Agent、桌面 Agent、机器人 Agent 也一样。LLM 需要的不只是 prompt,而是结构化、可验证、可更新的环境状态。
9.5 日志和审计是 Agent 产品的一部分
论文在伦理部分提到几个风险:用户和角色形成拟社会关系、错误推断带来伤害、deepfake 和定制化劝服、设计过程中过度依赖模拟人群。
作者建议平台保留输入和生成输出的审计日志。这个建议在今天更重要。越是长期运行、会记忆、会行动、会影响用户的 Agent,越不能只看一次输出是否“像样”。它需要可追溯的行为记录。
10. 我会怎么评价这篇论文
这篇论文的强处在于,它没有停留在“让 LLM 扮演 NPC”的 demo 层面,而是明确提出了一套外部架构:
- 记忆流保存经验
- 检索选择当前相关上下文
- 反思生成高层认知
- 计划维持长期连贯
- 沙盒环境把自然语言行为落回世界状态
它的问题也很清楚:
- 成本高
- 评估周期短
- 环境规模有限
- 角色过于礼貌合作
- 对底层模型偏差和幻觉继承明显
- 对 prompt hacking、memory hacking 等鲁棒性问题还没有系统解决
但这不影响它作为 Agent 架构论文的价值。很多后来的 Agent 讨论,其实都在不断重复它已经提出的几个问题:怎么记忆、怎么检索、怎么总结、怎么计划、怎么把自然语言行动落到真实环境里。
如果你只想带走一句话,我会选这句:
Generative Agents 证明了一个早期但重要的方向:LLM 负责生成和推理,Agent 架构负责记忆、状态、计划、环境约束和长期一致性。缺了后者,角色只是在聊天;有了后者,角色才开始像是在一个世界里生活。