与浏览器交互是我们开发流程中极为重要的一环,这里总结了我与浏览器交互的几种方法。
三类浏览器交互方案对比总结
这里把当前常见方案分成三类:专用业务 CLI、浏览器协议类工具,以及桌面级 Computer Use。它们看起来都能“让 AI 操作浏览器”,但实际的信息来源、动作执行方式和稳定性完全不同。
1. 专用业务 CLI:Lark-cli / bytedCli
这类工具本质上不是在操作浏览器,而是在绕过网页前端,直接调用目标系统的后端 API、OpenAPI 或内部 RPC。
典型链路是:
CLI 命令 -> 认证层 -> API Client -> 目标服务后端
浏览器主要只出现在登录授权环节:CLI 打开 SSO / OAuth 登录页,用户完成登录后,浏览器把授权 code 回跳到本地 callback,CLI 再用 code 换 token。之后读写文档、查 MR、触发流水线、创建 Meego,一般都是直接带 token 调服务端接口。
它拿到的信息是结构化 API 数据,不依赖页面 DOM、按钮位置或截图,所以稳定性最高。缺点是必须有对应 API,并且 API 权限、字段和业务语义要覆盖需求。
2. 浏览器协议类工具:bb-browser / agent-browser / Playwright CLI / Chrome DevTools MCP / Browser Use
这类工具是真正在控制浏览器,但通常不是通过操作系统层面“点屏幕”,而是连接浏览器暴露的自动化或调试接口。
常见底层包括:
- Chrome DevTools Protocol,简称 CDP
- Playwright driver / Playwright protocol
- WebDriver / WebDriver BiDi
- 面向 Agent 封装的 browser runtime
典型链路是:
Agent / CLI -> Browser automation wrapper -> CDP / Playwright / WebDriver -> Browser -> Web Page
它可以直接获取网页内部信息,例如当前 URL、DOM、Accessibility Tree、可点击元素、表单状态、截图、网络请求、cookie、localStorage 等。执行动作时,也可以通过 locator、DOM 节点、坐标、键盘事件或 JS 注入来完成点击、输入、跳转和等待页面变化。
Browser Use 属于这一类的更上层封装。以 Codex 的 Browser Use 为例,它不是把浏览器当成普通桌面窗口处理,而是通过 in-app browser runtime 暴露浏览器级能力,例如 tab 管理、页面跳转、Playwright 风格 locator、DOM snapshot、截图和视觉观察。Agent 看到的是“网页结构 + 当前画面”,动作则被翻译成浏览器自动化调用。
这类工具适合没有稳定 API、需要复用网页流程、调试页面、跑端到端测试、观察 Network 或操作复杂前端状态的场景。缺点是页面结构、选择器、异步加载和登录态变化都会影响稳定性。
3. 桌面级自动化:Computer Use
Computer Use 的抽象层级更低。它不是优先连接浏览器的 CDP 或 Playwright 接口,而是把浏览器当作一个普通桌面 App 来操作。
典型链路是:
Agent -> Computer Use -> 操作系统窗口 / 无障碍树 / 截图 -> 鼠标键盘事件 -> 桌面 App
它获取信息主要依赖两类信号:
- 当前窗口截图:让模型看到屏幕上的真实视觉状态
- 操作系统 Accessibility Tree:拿到按钮、输入框、菜单、文本等可访问性节点
它执行动作时更接近真实用户:点击某个无障碍元素或屏幕坐标、输入文字、按快捷键、滚动页面、拖拽窗口。因为它走的是桌面层,所以不仅能操作浏览器,也能操作 IDE、终端、系统弹窗、登录窗口、文件选择器和其他原生 App。
它的限制也来自这个层级:它通常不能天然读取浏览器内部的 Network、cookie、localStorage、DOM 细节或 JS 运行时状态,除非这些信息已经显示在页面或 DevTools 里。对网页任务来说,它比 Browser Use 更像“人眼 + 鼠标键盘”,语义信息少一些,但跨 App 能力更强。
横向对比
| 维度 | 专用业务 CLI | 浏览器协议类 / Browser Use | Computer Use |
|---|---|---|---|
| 核心通道 | 后端 API / OpenAPI / RPC | CDP / Playwright / WebDriver / browser runtime | 操作系统无障碍树、截图、鼠标键盘 |
| 是否真的操作浏览器 | 通常不操作,浏览器主要用于授权 | 是,直接控制浏览器和页面 | 是,但把浏览器当普通桌面 App |
| 信息来源 | API 返回的结构化数据 | DOM、AX Tree、URL、Network、Storage、截图 | 屏幕截图、桌面 Accessibility Tree |
| 动作方式 | 发 HTTP / RPC 请求 | locator 点击、DOM 操作、JS、浏览器输入事件 | 坐标点击、元素点击、键盘输入、滚动、拖拽 |
| 稳定性 | 最高,前提是 API 存在 | 中高,受页面结构和异步状态影响 | 中,受视觉布局、窗口焦点、缩放影响 |
| 覆盖范围 | API 覆盖到哪里就能做到哪里 | 主要覆盖网页和浏览器上下文 | 覆盖整个桌面和所有可见 App |
| 适合场景 | 文档、MR、流水线、Meego 等确定业务操作 | 网页调试、E2E、无 API 页面、读取页面状态 | 系统弹窗、文件选择器、IDE、终端、跨 App 工作流 |
| 主要短板 | 没有 API 就做不了 | 对页面变化敏感,需要处理等待和定位 | 不懂网页内部状态,精细调试能力弱 |
选择原则
优先级可以简单记成:能走 API 就走业务 CLI;必须经过网页流程时用 Browser Use / Playwright / CDP;任务跨出浏览器、涉及系统 UI 或其他桌面 App 时用 Computer Use。
更直白地说:
业务 CLI:像后端客户端,直接请求服务端
Browser Use / Playwright / CDP:像测试框架,直接控制网页
Computer Use:像真人用户,通过屏幕和鼠标键盘操作电脑
所以三者不是谁替代谁,而是工作层级不同。稳定的业务自动化更适合 CLI;开放式网页任务更适合 Browser Use 或 Playwright;需要穿过浏览器、IDE、终端、文件选择器和系统弹窗的任务,Computer Use 的泛化能力更强。
具体用途
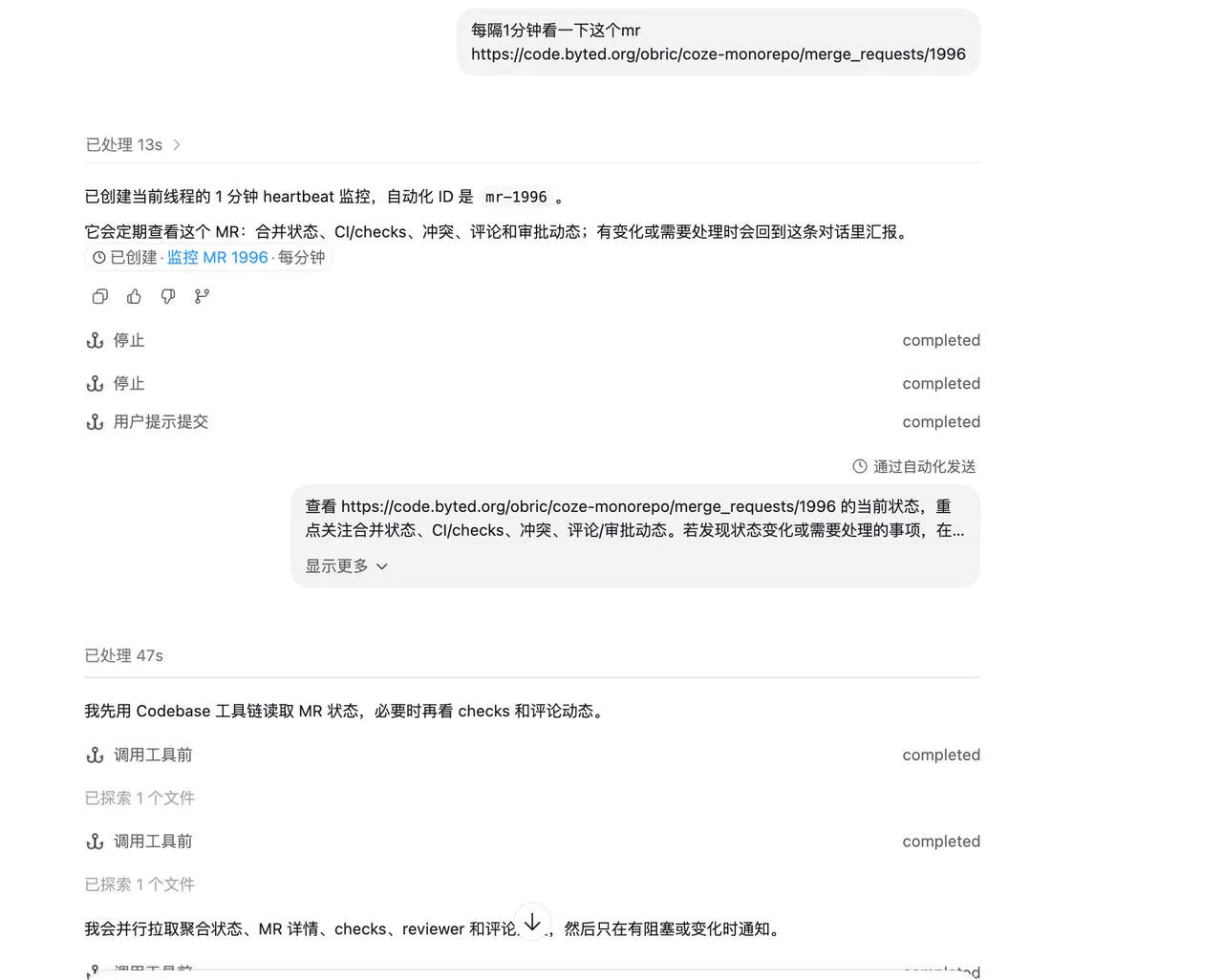
自动创建 Meego、创建 BITS 流水线、创建 MR、监听 MR,进而修改 CI / CD 错误、自动回复评论。
case 1

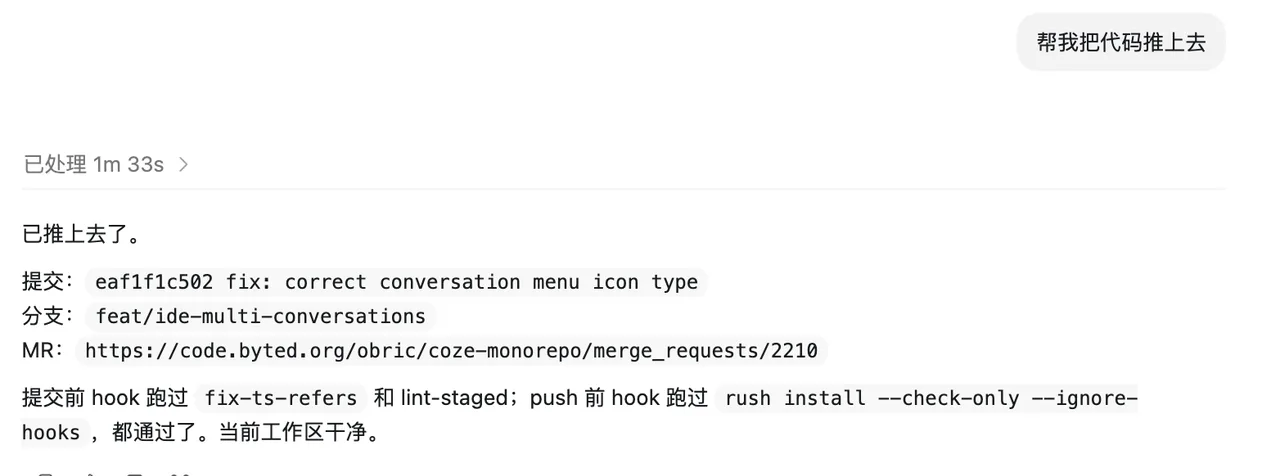
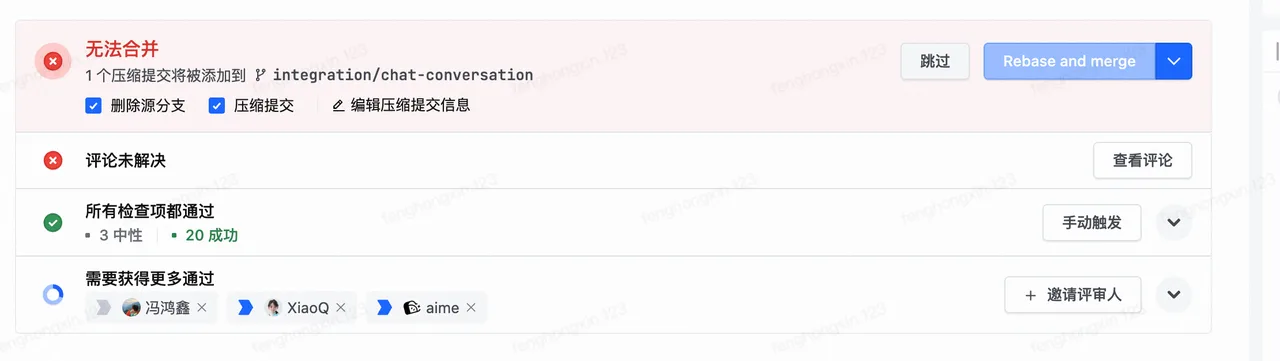
case 2
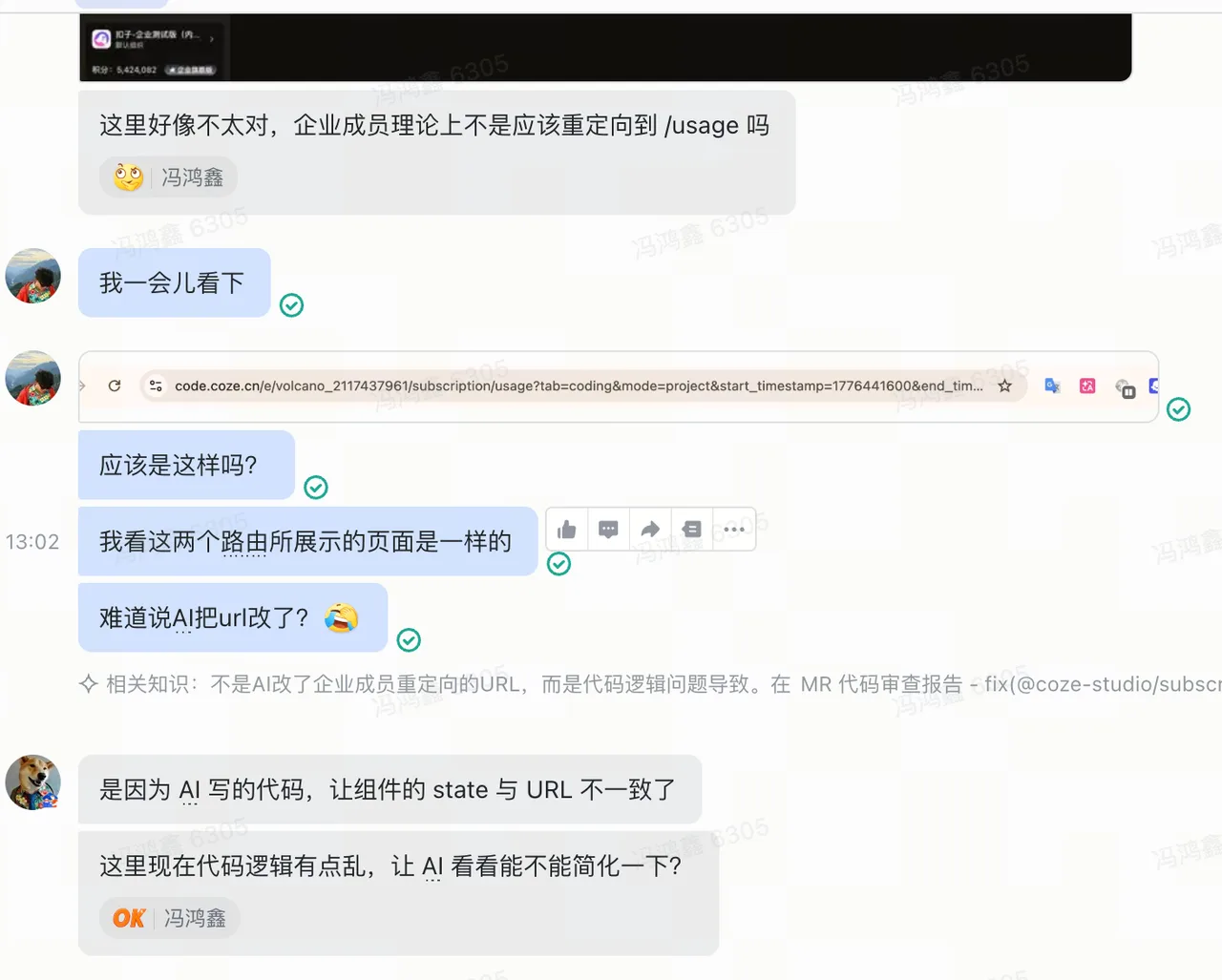


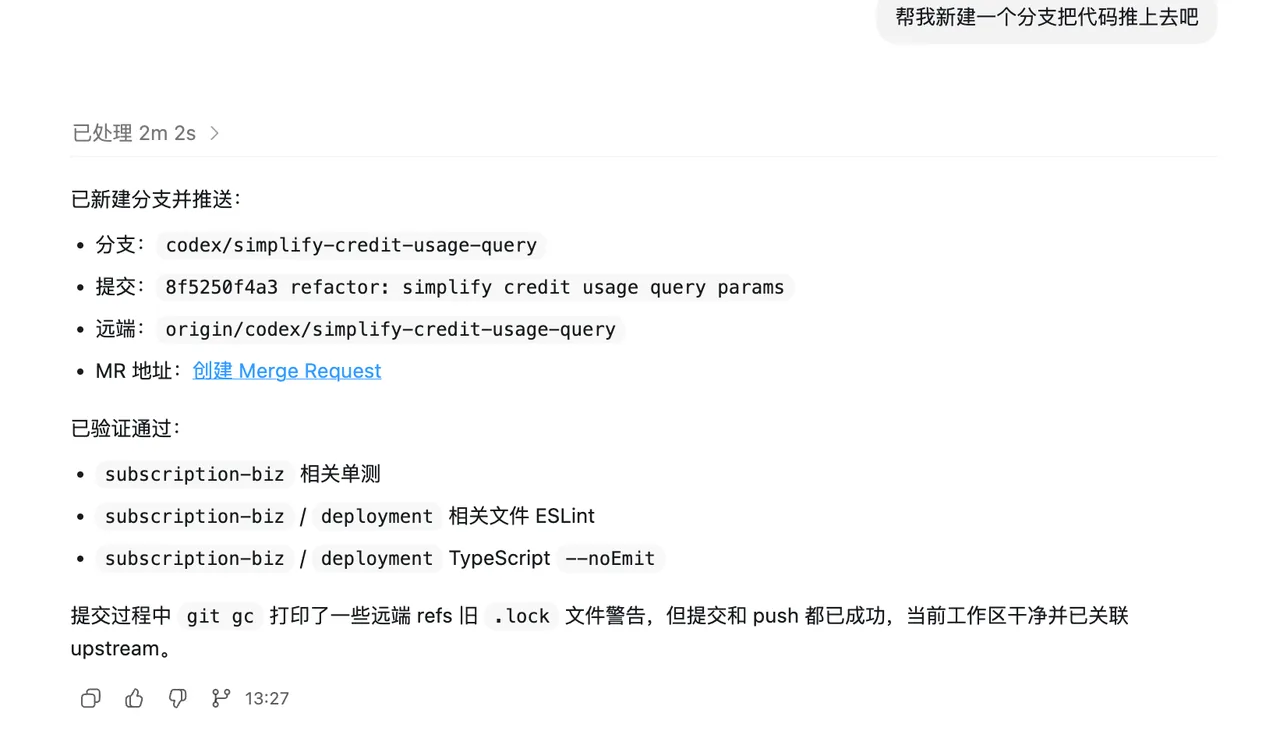

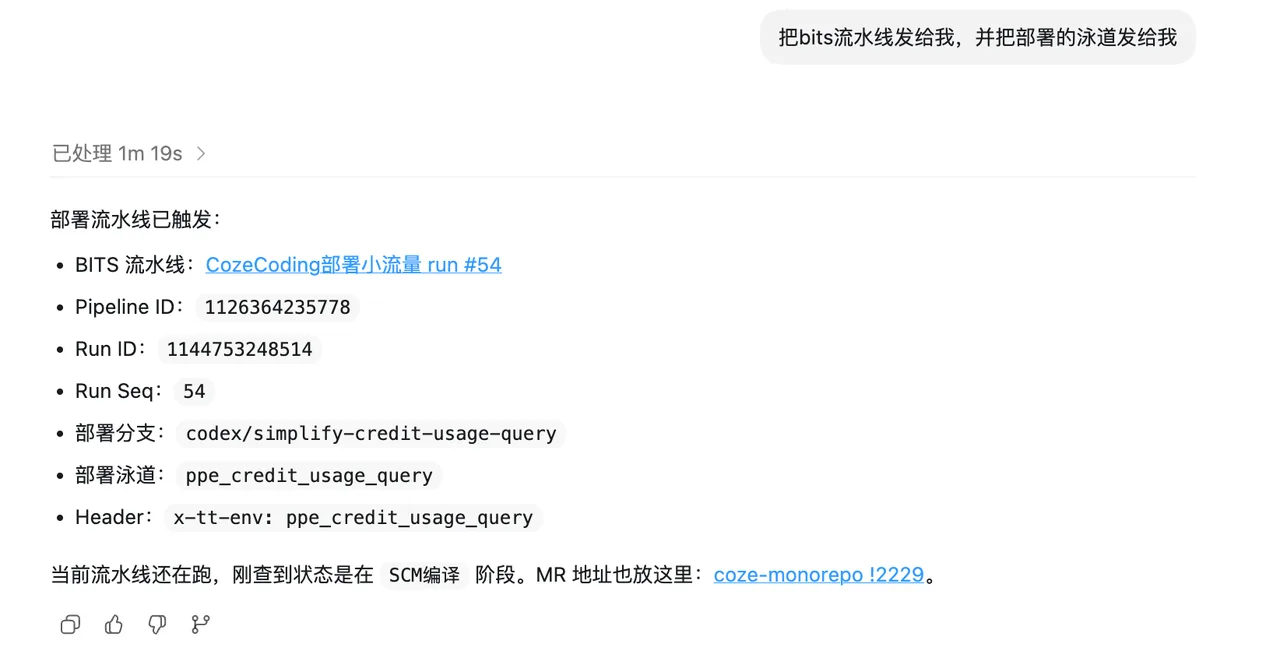

case 3
case 4
自动监听自动修改。